Scripts, Macros, Bindings and 0xbaadf00d
OK, I guess I should go back from my area where I've recently worked on data/project migration improvements (more about this at bottom of this page) and spend some more hours on scripting stuff.
I think mainly about helping with moving it up to kofficelibs. Contribute with scripting design and implementation and macro bindings, making it easier adaptable for other KOffice apps, most notable Krita.
Sebastian is a chief in our scripting department, his awesome work deserves support. We all need to make KROSS fit well for relatively different apps like Kexi and Krita.
I'll tell this for myself: a main difference you need to know is that we're not fans using automatic bindings for this. User-level scripting won't work this way. Look at how SUN's UNO exposed in StarBasic - it's relatively more ugly to instantiate dozens interfaces impleemntation to get an access to, say, a spreadsheet cell or to get data loaded from a datas source.
It's not how user's world looks like. Users want one, or at most: two API layers - that's all.
They won't love APIs created by casting C/C++ APIs to Python/Javascript/Basic/whateverlanguageyoulike, 1-to-1. Audience for app level scripting is not the same as audience for PyQt/PyKDE. The task of providing must be perfomed by human being, so the effect will be more flat, not so powerfull, but easier to understand and remember API.
The resulting API that use familiar metaphores, like spreadsheet cell or data table row, and lacks many abstract classes and layers virtually nobody will want to study except me and you.
On the other hand, if your power user, "one in a million", complains she/he cannot "override a method class X", feel free to propose her/him just to use C++ (or full PyQt/PyKDE?) so she/he can implement extension in a form of plugin. Or she/he can just contribute her/his code to your app directly. The power user will be able to do so, if it's works of additional work. In the same time, the rest (or majority) of users will be quite happy not to see bloated scripting APIs.
And finally, for the rest of users, who are not able to do scripting but want automation, we have macros
- even more simplified version of the original API, most often allowing only linear step-by-step processing (i.e. no looping and algorithms) - simple and easy to understand.
In the Kexi department, I've got a few reports about problems with importing MS Access files. Last week many usability and stability issues have been fixed; now it's not a problem to import Access .mdb files. Funny, but on curent machine, more than 30 MB files are imported faster than opening them in MS Access.
To have a well known data sets any (former?) MS Access user can refer to, I've successfully imported Northwind sample database distibuted with every MS Access package.
Importing idea:
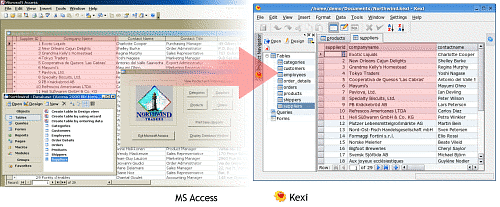
The Import Wizard - slideshow:

(click here for a larger version)
As for now only tables (schema and data) are imported. We already know it will be easy to import database relationships as soon as Kexi allows to present and edit them in user-friendly way. Queries and Forms are pretty much more obfuscated in .mdb files, after some research I noticed it's possible to hack on top of mdbtools. Summing up, virtually every open database tool utilizes mdbtools to read to .mdb files but Kexi raises the bar of accuracy a bit more.
You would say 'lol' to see what (temporary) hacks are sometimes used to get software to work when we're trying to keep glib- and Qt-based software (read: C and C++) together. Still, kudos to mdbtools hackers, for their reverse-engineering skills - especially while MS Access authors decided not to initialize files with zeros, what made looking at the structure (filled with random garbage) very boring :o
Notice 0xbaadf00d below :)
if (IS_JET4(mdb)) cur_pos += 4;
do {
pidx = g_ptr_array_index (table->indices, idx_num++);
- } while (pidx && pidx->index_type==2);
+ } while (pidx && pidx!=(MdbIndex*)0xbaadf00d && pidx->index_type==2);
/* if there are more real indexes than index entries left after
removing type 2's decrement real indexes and continue. Happens
on Northwind Orders table.
*/
- if (!pidx) {
+ if (!pidx || pidx==(MdbIndex*)0xbaadf00d) {
table->num_real_idxs--;
continue;
}
PS: Let me know if you have a sample MS Access database(s) that you can share with me for testing purposes.
PS2: After importing Northwind.kexi database file is 280KB large, while original Northwind.mdb file (with anything but tables removed) is 900KB. Both files were compacted (aka VACUUM in SQL). So here you can see Kexi as not only faster solution but also producing 3 times smaller files.